知识图谱
什么是知识图谱
为提高搜索效率,优化搜索质量,2012年,Google首先提出知识图谱这以概念,以知识图谱为底层技术支持的搜索引擎,用户不再需要通过不停的点击链接来获取自己想要的信息,实现智能搜索。
知识图谱定义
知识图谱,是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是“实体-关系-实体”三元素,以及实体及其相互属性-值对,实体间通过关系相互联结,构成网络的知识结构。
这个定义的含义:
- 知识图谱本身是一个具有属性的实体通过关系链接而成的网状知识库.从图的角度来看,知识图谱在本质上是一种概念网络,其中的节点表示物理世界的实体(或概念),而实体间的各种语义关系则构成网络中的边.由此,知识图谱是对物理世界的 一种符号表达。
- 知识图谱的研究价值在于,它是构建在当前Web基础之上的一层覆盖网络(overlay network),借助知识图谱,能够在Web网页之上建立概念间的链接关系,从而以最小的代价将互联网中积累的信息组织起来,成为可以被利用的知识.
- 知识图谱的应用价值在于,它能够改变现有的信息检索方式,一方面通过推理实现概念检索(相对于现有的字符串模糊匹配方式而言);另一方面以图形化方式向用户展示经过分类整理的结构化知识,从而使人们从人工过滤网页寻找答案的模式中 解脱出来。
知识图谱的架构
1. 知识图谱逻辑架构
数据层
在知识图谱数据层,知识以事务(fact)为单位存储在图数据库,如果以“实体-关系-实体”或者“实体-属性-性质”三元组作为事务的基本表达方式,存储在图数据库中的所有数据将构成庞大的实体关系网络,形成知识的“图谱”。
模式层
模式层是知识图谱的核心,在模式层存储的是经过提炼的知识,通常采用本体库来管理知识图谱的模式曾,借助本体库对公理、规则和约束条件的支持能力来规范实体、关系以及实体的类型和属性等对象之间的联系,本体在知识图谱中的地位相当于知识库的模具,拥有本体库的冗余知识很少。
知识图谱的一般构建结构,知识图谱构建过程从原始数据出发,采用一系列自动或者半自动技术手段,从原始数据中提取出知识,并将其存储到知识库的数据层和模式层的过程。这是一个迭代的过程,根据知识获取的逻辑,每一轮迭代包含三个阶段:信息抽取、知识融合以及知识加工。
2. 知识图谱构建
自顶向下构建
所谓自顶向下构建是指借助本体和模式信息,加入到知识库中。
自底向上
所谓自底向上构建,则是借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的新模式,经过人工审核后,加入知识库中。
3. 知识图谱构建过程
信息抽取
信息抽取是一种自动化地从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息的技术。涉及的关键技术包括:实体抽取、关系抽取和属性抽取。
1.实体抽取
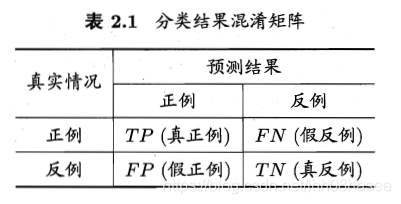
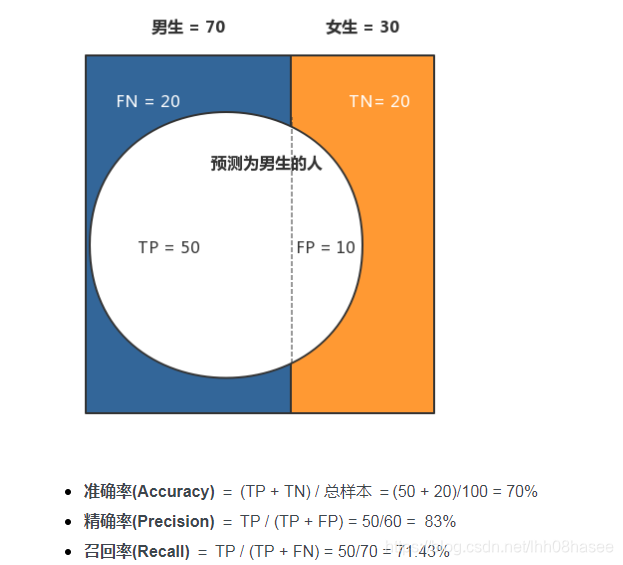
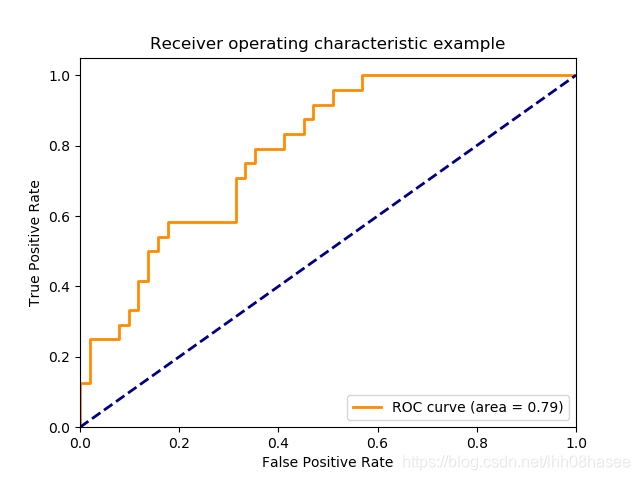
指从文本数据集中自动识别出命名实体,实体抽取质量(准确率、召回率)对整个知识获取效率影响极大,是信息抽取最为基础和关键的部分。
2.关系抽取
文本语料经过实体抽取,得到的是一系列离散的命名实体,为了得到语义信息,还需要从相关语料中提取出实体之间的关联关系,通过关系将实体联系起来,形成网状的知识结构。
早期相关研究主要通过人工构造语法和语义规则,这种方法有两个不足:
- 要求制定规则的人对特定领域有深入理解和认知
- 制定工作量大,并且难以扩展到其他领域
随后出现了一系列关于实体关系的模型研究:
- 机器学习方法(统计学)
- 基于特征向量或核函数的有监督学习方法(缺点需要进行大量的人工标注来确保算法有效性)
- 半监督、无监督学习方法
3.属性抽取
属性抽取的目标是从不同信息源中采集特定实体的属性信息,例如针对某个公共人物,可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。属性抽取技术从多种数据来源中汇集这些信息,实现对实体属性的完整勾画。
知识融合(knowledge fusion)
目的:将知识抽取中包含的冗余和错误信息进行清理和整合
主要包含两个内容:实体链接和知识合并。
1.实体链接
是指对从文本中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。基本思想是根据给定的实体 指称项 ,从知识库中选取一组候选实体对象,然后通过相似度计算将 指称项 链接到正确的实体对象。
实体链接的基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,然后通过相似度计算将指称项链接到正确的实体对象。
实体链接的一般流程:
- 从文本中通过实体抽取得到实体指称项
- 进行实体峭岐和共指消解,判断知识库中的同名实体与之是否代表不同的含义以及知识库中是否存在其他命名实体与之表示相同的含义;
- 在确认知识库中对应的正确实体对象后,将该实体指称项链接到知识库中对应实体。
关于消除歧义的补充:
- 实体消歧
消除同名实体产生的歧义问题。例如“李娜”这个名词可能指代中国顶级网球运动员,也可能指代现在在某高校就读的研究生。通过实体消岐结合当前语义环境来分辨实体的具体指代是什么。(聚类) - 共指消解
解决多个指称项对应于同一实体对象的问题。例如“母亲”和“妈妈”在汉语中是对同一个实体的不同称谓,它们的意思是相同的。
2.知识合并
指将两个内容相近的知识库进行融合,形成一个更大的知识库。
- 合并外部知识库
主要处理两方面的问题:
- 数据层融合:包括实体的指称、属性、关系以及所属类别等
其主要研究问题是如何避免实例以及关系冲突等问题(冗余问题) - 模式层融合:将新得到的本体融入到已有的本体库中。
- 合并关系数据库
对两个关系型数据库求左合并,右合并,笛卡尔积等操作。(关于这个我可能解释的比较狭义但是好像就是这样的)
知识推理
是指从知识库中已有的实体关系数据触发,经过计算机推理,建立实体的新关联,从而拓展和丰富知识网络。例如(曹操,父子,曹丕),(曹丕,兄弟,曹植),可以推导出(曹操,父子,曹植)。
知识图谱相关PAAS服务
百度AI开放平台
输入:
待标注的文本字符串(utf8编码,最多64个汉字)1
2// 输入示例
curl -X POST 'https://aip.baidubce.com/rpc/2.0/kg/v1/cognitive/entity_annotation?access_token=【用户access_token】' -H 'content-type: application/json' -d '{"data": "刘德华的老婆"}'
输出:(示例)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32// 输出示例
{
"log_id": 6367018173853945311,
"entity_annotation": [
{
"status": "LINKED",
"confidence": "0.991616",
"concept": {
"level1": "人物",
"level2": "文化人物,娱乐人物"
},
"_bdbkKgId": "114923",
"mention": "刘德华",
"_bdbkUrl": "http://baike.baidu.com/item/%E5%88%98%E5%BE%B7%E5%8D%8E/114923",
"offset": "0",
"desc": "中国香港男演员、歌手、词作人"
},
{
"status": "LINKED",
"confidence": "0.817889",
"concept": {
"level1": "语言文化",
"level2": "文字词汇"
},
"_bdbkKgId": "827",
"mention": "老婆",
"_bdbkUrl": "http://baike.baidu.com/item/%E8%80%81%E5%A9%86/827",
"offset": "4",
"desc": "汉语词语"
}
]
}
知识图谱的应用领域
智能问答
降低了人机交互门槛,用户可以通过关键词向网页发送请求得到他们想要的答案。
智能推荐
例如Facebook的Graph Search,用户查询产品信息时仅需输入关键词,以知识图谱为基础的智能推荐就会向用户输出产品相关信息。
金融领域
金融领域是知识图谱最早、最广泛的应用领域之一,目前最常用的主要是风险控制和智能投顾两方面。
例如金融知识图谱,对数据进行智能分析,当用户进行投资理财时,可以根据提取出来的信息,结合用户实际需求,为用户智能推荐理财产品。
数据获取来源
- 爬虫
- 数据库获取
数据预处理
- 数据清洗
- 知识抽取
导入数据到知识图谱
- 数据筛选(决定哪些数据需要到知识图谱系统,性能,业务要求)
- 知识图谱设计(类似数据库设计)
- 批量导入(初次导入基础数据)
- 增量导入
本体论
本体论(Ontology),是探究世界的本原或基质的哲学理论。“本体论”一词是由17世纪的德国经院学者P·戈科列尼乌斯首先使用的。
传统上的本体含义,是一个哲学的分支,即形而上学,本体论一般包含了有关所有的实体的存在或者一些可能会存在的问题,以及实体之间如何被归类研究对立的问题,如何在层次的体系结构中,根据相互作用和差异上进行分类的问题。本体论还有个通俗易懂的定义是,它是对事物“存在”性的定性检验。
关于本体论的例子:
基因本体论(gene ontology)
基因本体(Gene Ontology,GO)是一个在生物信息学领域中广泛使用的本体,它涵盖生物学的三个方面:细胞组分、分子功能、生物过程。

基因本体是一个有向无环图(DAG)型的本体。目前,GO中使用了is_a和part_of和regulates三种关系。

本体论与知识图谱的区别
例如要对档案领域的知识库分类,这个分类本身就是本体。比如档案数据分为毕业生类和学校文件类,毕业生类又分为本科生类、研究生类;关于每个分类下又有不同的数据信息,每种信息对应着不同的实体,每个实体有其不同的属性值,可以将其抽象成为一个三元组,例如(毕业生A,毕业年份,2017),这个三元组就是知识图谱中的基本结构了。
由于知识图谱这个概念是由Google提出,而知识库的概念没有明确的提出,可以将其理解为是知识数据库,即所有数据的集合体,包含知识和本体,例如Wiki百科就可以理解为一个半结构化的知识库。(我的理解是知识库是广义的知识图谱,知识图谱最终构建的逻辑结构为一个图)
还有一个浅而易懂的例子,对于概念型的三元组(老虎,科,猫科),如果将猫科定义为一个本体,则这个三元组就反映了本体与实体之间的关系。
参考:
(1)知识图谱基础知识
(2)田莉霞.知识图谱研究综述[J].软件,2020,04:67-71.
(3)段宏. 知识图谱构建技术综述[J]. 计算机研究与发展(03).
(4)百度AI开放平台
(5)百度百科-本体论
(6)Paulheim H , Cimiano P . Knowledge graph refinement: A survey of approaches and evaluation methods[J]. Semantic Web, 2016, 8(3):489-508.