AI测试
什么是AI测试
人工智能(AI)是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学(定义)。人工智能利用机器学习技术,通过对现有的经过处理(筛选、消噪、过滤等)的数据,不断进行矫正(设置阀值等方法)机器模型的输出,此过程称为训练,期望通过训练可以得到在未来新数据上有良好表现的模型,从而投入生产。
AI测试内容
1. 模型评估测试
模型评估主要是测试 模型对未知新数据的预测能力,即泛化能力。
泛化能力越强,模型的预测能力表现越好。而衡量模型泛化能力的评价指标,就是性能度量(performance measure)。性能度量一般有错误率、准确率、精确率、召回率等。
参数以及说明:
Accuracy(准确率)
Precision(精确率)
Recall(召回率)
F1值
P-R(Precision-recall )曲线
ROC曲线
AUC值
Kappa系数
OOB误差
对于二值分类器,或者说分类算法,如分类猫和狗,分类性别男和女。
TP、FP、TN、FN,即:
True Positive, False Positive, True Negative, False Negative
预测值与真实值相同,记为T(True)
预测值与真实值相反,记为F(False)
预测值为正例,记为P(Positive)
预测值为反例,记为N(Negative)
TP:预测类别是正例,真实类别是正例
FP:预测类别是正例,真实类别是反例
TN:预测类别是反例,真实类别是反例
FN:预测类别是反例,真实类别是正例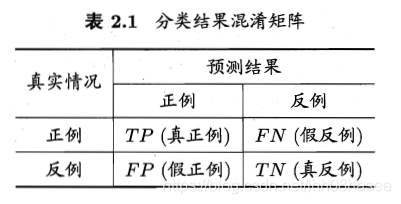
例子
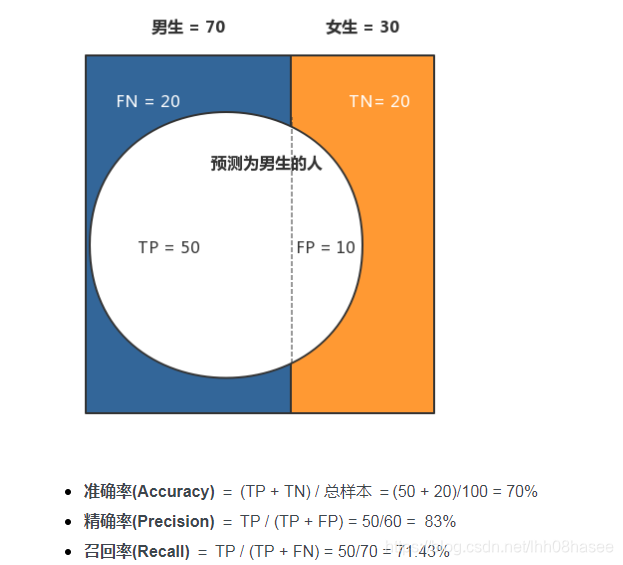
AUC&ROC曲线
受试者操作特征曲线(ROC),这一点网上已经说烂不再赘述,用来衡量二分类问题中的模型性能。
SKLEARN接口文档代码示例
1 | import numpy as np |
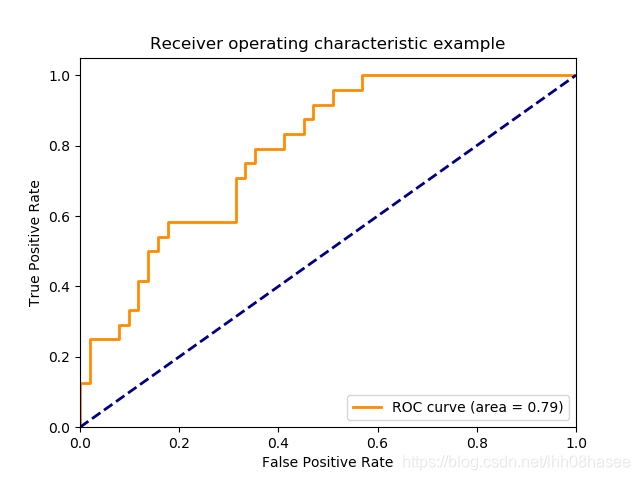
P-R曲线
P-R曲线用来衡量分类器性能的优劣,横轴为recall ,纵轴为precision。
P-R 曲线越靠近右上角性能越好。
如果有多个分类器,则可以画出P-R曲线,若一个分类器A的P-R曲线把另外一个分类器B覆盖,则在一方面可以说明 A的分类器性能比B分类器好。
有交叉时,用平衡点(BEP)来衡量。平衡点即precision 等于 recall 时的值。那么可以认为A优于B。
画出P-R曲线:
算法对样本进行分类时,通常都会有个阈值,或者超参数,需要调。
不同的阈值时,就可以得出不同的精确率和召回率,从而画出P-R曲线图。
OOB误差
随机森林算法模型误差评价
2. 稳定性测试
稳定性/鲁棒性主要是测试算法多次运行的稳定性;以及算法在输入值发现较小变化时的输出变化。
如果算法在输入值发生微小变化时就产生了巨大的输出变化,就可以说这个算法是不稳定的。
3. 系统测试
将整个基于算法模型的代码作为一个整体,通过与系统的需求定义作比较,发现软件与系统定义不符合或与之矛盾的地方。
系统测试主要包括以下三个方面:
- 项目的整体业务流程
- 真实用户的使用场景
- 数据的流动与正确
4. 接口测试
接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。
5. 文档测试
文档测试是检验用户文档的完整性、正确性、一致性、易理解性、易浏览性。
在项目的整个生命周期中,会得到很多文档,在各个阶段中都以文档作为前段工作成果的体现和后阶段工作的依据。为避免在测试的过程中发现的缺陷是由于对文档的理解不准确,理解差异或是文档变更等原因引起的,文档测试也需要有足够的重视。
6. 性能测试
7. 白盒测试
AI测试流程
AI测试分为五个步骤,测试需求分析、测试环境准备、测试数据准备与验证、AI测试执行与分析、模型上线与监控。
AI测试需求分析
AI测试需求分析与软件开发的需求分析要求基本一致,需要明确测试对象、测试范围、测试的方法和工具、测试的准则等。AI测试需求分析需要通过开发、测试、运营共同参与讨论,确定AI系统测试通过的准则。由于AI开发具有一定的不确定性,还需要根据实际情况去定义可允许的风险,风险可根据技术的限制和社会共识来确定。
测试环境准备
AI的算法,比如推荐系统、搜索引擎、图像分类、自然语言处理都依赖于大数据基础架构,因此AI算法模型的测试环境准备,通常需要考虑数据量、计算量、测试时间等因素。此外,AI测试需要高效的持续测试,所以AI测试尤其需要测试环境快速部署的能力。
测试数据准备与验证
AI测试与机器学习一样,需要一定量测试数据去进行模型的评估与测试。测试的数据集要根据真实环境下用户产生的数据情况去划分,可以遵守如下原则:
- 测试数据与训练数据的比例要合适
- 测试数据与训练数据需要独立同分布
- 测试数据与训练数据正负样本的比例也需要尽量保持一致
- 对于有监督的模型,测试数据的标签需要保证正确
AI系统测试与分析
模型离线评估主要是评测AI模型对未知新数据的预测能力,即泛化能力。泛化能力越强,模型的预测能力越好。可靠性测试,包括了鲁棒性、可用性、容错性、易恢复性等指标。对于无人驾驶、人脸识别等安全攸关的AI系统,需尽可能采用异常数据来进行测试,如对抗样本、易出错的样本等;对于推荐系统和搜索引擎等智能程序则需要测试反作弊能力。
AI模型上线与监控
AI模型上线后,根据实际业务每隔几天或几星期,对模型各类指标进行评估。指标应设置对应阀值,当低于阀值时应触发报警。如果模型随着数据的演化而性能下降,说明模型在新数据下性能不佳,就需要利用新数据重新训练模型。此外,在一些场景中,我们还需要对用户输入数据进行监控。
测试结果
通过测试文档以及各种测试的资料,可以整合成一个整个文档。通过文档说明可以更正所有测试的内容。

参考博客
人工智能测试方法–释梦石