URL
URL
1、URL(Uniform Resource Locator)统一资源定位符,表示Internet上某一资源的地址,协议名:资源名称
TCP
1、TCP协议是面向连接的、可靠的、有序的、以字节流的方式发送数据,通过三次握手方式建立连接,形成传输数据的通道,在连接中进行大量数据的传输,效率会稍低
2、Java中基于TCP协议实现网络通信的类
客户端的Socket类
服务器端的ServerSocket类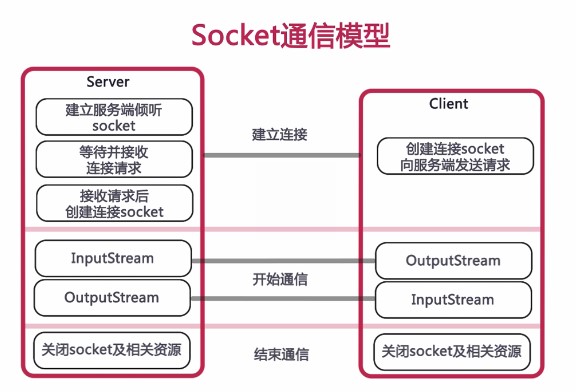
3、Socket通信的步骤
① 创建ServerSocket和Socket
② 打开连接到Socket的输入/输出流
③ 按照协议对Socket进行读/写操作
④ 关闭输入输出流、关闭Socket
4、服务器端:
① 创建ServerSocket对象,绑定监听端口
② 通过accept()方法监听客户端请求
③ 连接建立后,通过输入流读取客户端发送的请求信息
④ 通过输出流向客户端发送乡音信息
⑤ 关闭相关资源
5、客户端:
① 创建Socket对象,指明需要连接的服务器的地址和端口号
② 连接建立后,通过输出流想服务器端发送请求信息
③ 通过输入流获取服务器响应的信息
④ 关闭响应资源
6、应用多线程实现服务器与多客户端之间的通信
①服务器端创建ServerSocket,循环调用accept()等待客户端连接
② 客户端创建一个socket并请求和服务器端连接
③ 服务器端接受苦读段请求,创建socket与该客户建立专线连接
④ 建立连接的两个socket在一个单独的线程上对话
⑤ 服务器端继续等待新的连接